Next: METHODOLOGY
Up: R. Clapp: Ray based
Previous: R. Clapp: Ray based
Following the methodology of Clapp and Biondi (1999), I will
begin by considering a regularized tomography problem.
I will linearize around an initial slowness estimate and find
a linear operator in the vertical
traveltime domain 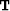 that relates change in slowness
that relates change in slowness 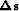 with our change in traveltimes
with our change in traveltimes 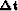 .We will write a set of fitting goals,
.We will write a set of fitting goals,
| 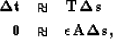 |
|
| (1) |
where 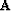 is our steering filter operator Clapp et al. (1997) and
is our steering filter operator Clapp et al. (1997) and  is a
Lagrange multiplier.
However, these
fitting goals don't accurately describe what
we really want. Our steering filters are based on our
desired slowness rather than change of slowness. With this
fact in mind, we can rewrite our second fitting goal as:
is a
Lagrange multiplier.
However, these
fitting goals don't accurately describe what
we really want. Our steering filters are based on our
desired slowness rather than change of slowness. With this
fact in mind, we can rewrite our second fitting goal as:
| 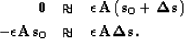 |
(2) |
| (3) |
Our second fitting goal can not be strictly defined as regularization
but we can still do a preconditioning substitution Fomel et al. (1997),
giving us a new set of fitting goals:
| 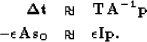 |
|
| (4) |
The trouble is how to estimate . Previously
I have calculated semblance at various hyperbolic
moveouts. I then picked the moveout corresponding to the maximum
semblance. To calculate 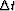 I converted my picked moveout parameter back to
a depth error
I converted my picked moveout parameter back to
a depth error 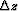 , which is converted into a travel time.
Following the
methodology of Stork (1992),
, which is converted into a travel time.
Following the
methodology of Stork (1992),
| 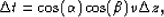 |
(5) |
where,
 is the local dip,
is the local dip, 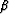 is the opening angle at the reflection point,
and v is the local velocity.
This approach is effective in areas which are generally flat
and have a sufficient offset coverage, but as
shown in Biondi and Symes (2002) it runs into
problems when these conditions aren't met.
is the opening angle at the reflection point,
and v is the local velocity.
This approach is effective in areas which are generally flat
and have a sufficient offset coverage, but as
shown in Biondi and Symes (2002) it runs into
problems when these conditions aren't met.
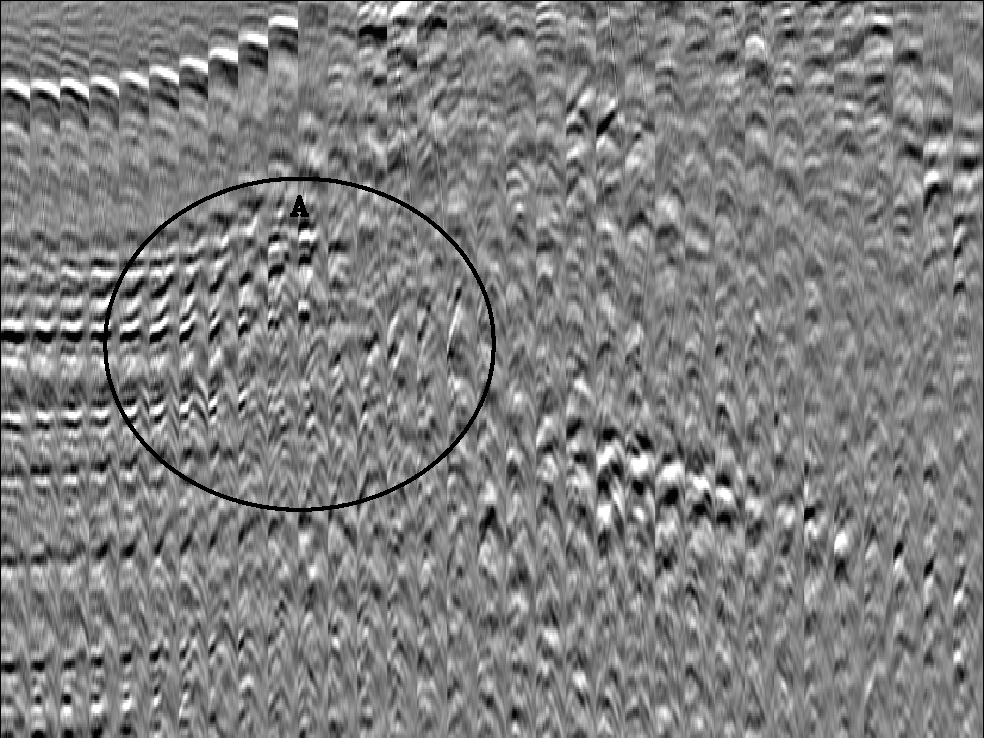
A real data example of this problem can be seen in
Figure 1. Note the ``hockey stick'' behavior
seen at `A'. If we follow the procedure of Stork (1992) we get
unreasonably large travel time errors. Clapp (2002)
shows that if we use these points for back projection,
we get too large of velocity changes, which can lead to
instability of the tomography problem.
gathers
Figure 1 Every 5th gather to the left edge
of a salt body. Note the coherent, ``hockey stick'' behavior
within `A'.





Next: METHODOLOGY
Up: R. Clapp: Ray based
Previous: R. Clapp: Ray based
Stanford Exploration Project
11/11/2002