Next: NMO-Stacking process
Up: Marine Data Results
Previous: Computing aspects
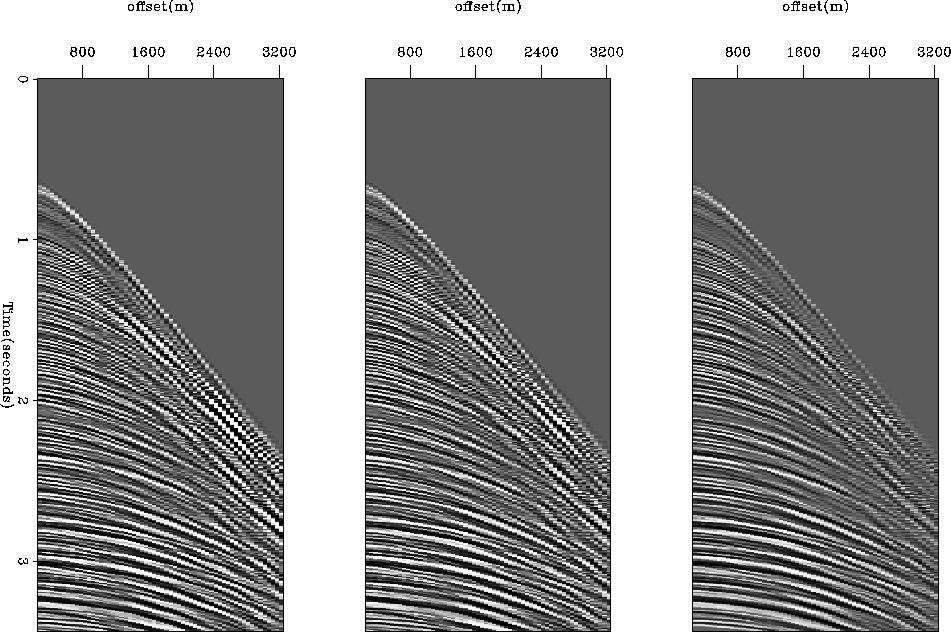
Figure 3 shows the result of the inversion for one CMP. Since
the Mobil AVO dataset does not include very complex structures with strong
velocity contrasts, this panel illustrates what happens for all the gathers.
The left panel shows the input data. The other panels display the reconstructed
data using the different schemes. Note that the l2 and l1 inversions give
similar results and that the l1 regularization doesn't converge as well.
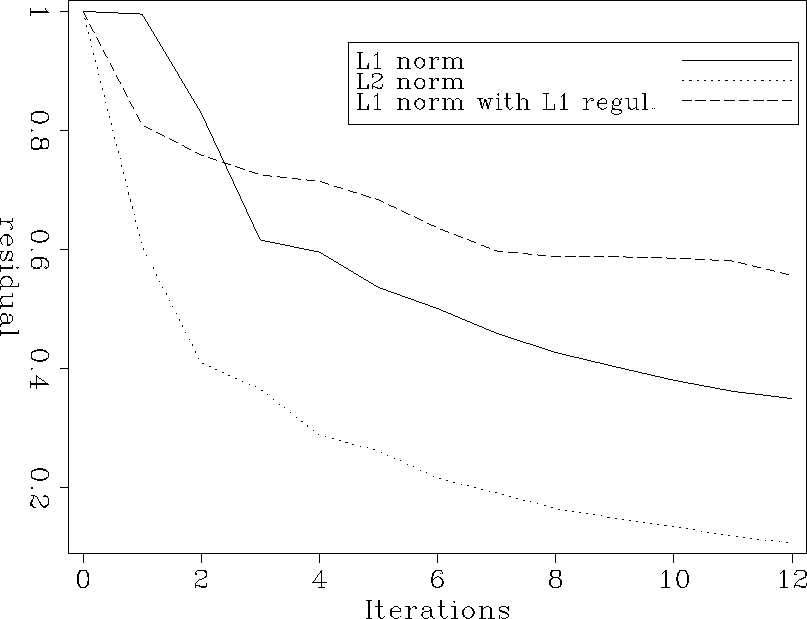
Figure 4 highlights this difference
between the different problems. The best convergence is achieved using least-squares and
the worst is achieved with the l1 regularization. In my implementation, however, the
l1 problem with or without regularization was solved using twice as many iterations as
with l2. Figure 5 shows the differences between the input data and
the remodeled data. It appears that the l1 norm with l1 regularization
encounters some difficulties in fitting the far offset data. Note
that the l1 norm and the l2 norm are both comparable. This is expected since
the data are not strongly noisy.
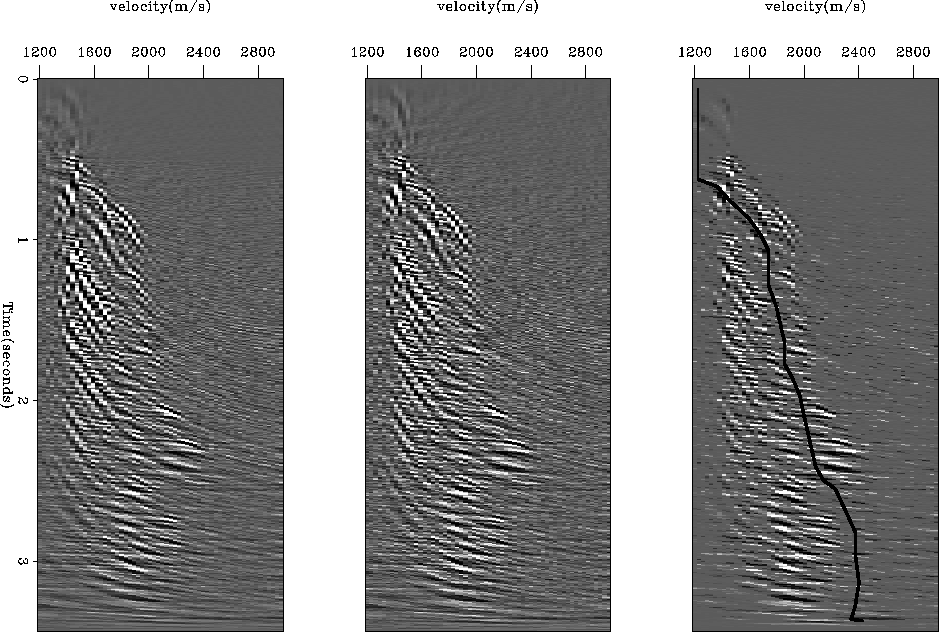
Differences arise in favor of the l1 regularization when we look at the model space
(Figure 6), however. The l1 and l2 results are again very similar and the
l1 norm with l1 regularization appears spikier. This result is consistent with the theory
(see Theory section). The spiky result is then used to define the limit between
primaries and multiples (black line in the right panel of Figure 6).
A mask is defined accordingly and the primaries are muted out in the model space.
The next step consists of remodeling the multiples back
in the data space, applying the hyperbola superposition principle (operator H).
Figure 7 shows the predicted multiples. Note that for the
three inversion schemes, some primaries remain. This is particularly annoying to us
in our attempt to produce true amplitude multiple-free gathers.
Figure 8 displays the result of the multiple attenuation process.
The three methods display similar results. Nonetheless, at far offset, the
l1 regularization shows more energetic events. This is consistent with Figure
5 where we showed that the l1 regularization was unable
to fit this part of the data.
comp_dat
Figure 3 Left: input data. Middle-left: l2 reconstructed data.
Middle-right: l1 reconstructed data. Right: l1 with l1 regularization reconstructed data.




 residual
residual
Figure 4 Comparison of the convergence for different inversion
schemes for one CMP gather.
diff
Figure 5 Left: input data. Middle-left: l2 residual. Middle-right: l1 residual. Right: l1 with l1 regularization residual.
comp_scan
Figure 6 Left:l2 model. Middle: l1 model. Right: l1 with l1 regularization. The line shows the limit of the muting process that separates ``guessed''
multiples on the left from ``guessed'' primaries on the right for the spiky model.
comp_mult
Figure 7 Predicted multiples. Left: l2 multiples. Middle: l1
multiples. Right: l1 with l1 regularization multiples.
comp
Figure 8 Gathers after multiple attenuation. Left: input data with multiples. Middle-left: l2 multiple attenuation. Middle-right: l1 multiple attenuation. Right: l1 with l1 regularization multiple attenuation.
Next: NMO-Stacking process
Up: Marine Data Results
Previous: Computing aspects
Stanford Exploration Project
4/27/2000