Next: KIRCHHOFF MIGRATION
Up: SPLIT-STEP MIGRATION
Previous: Small problem results
Next, we analyze the results for the large problem.
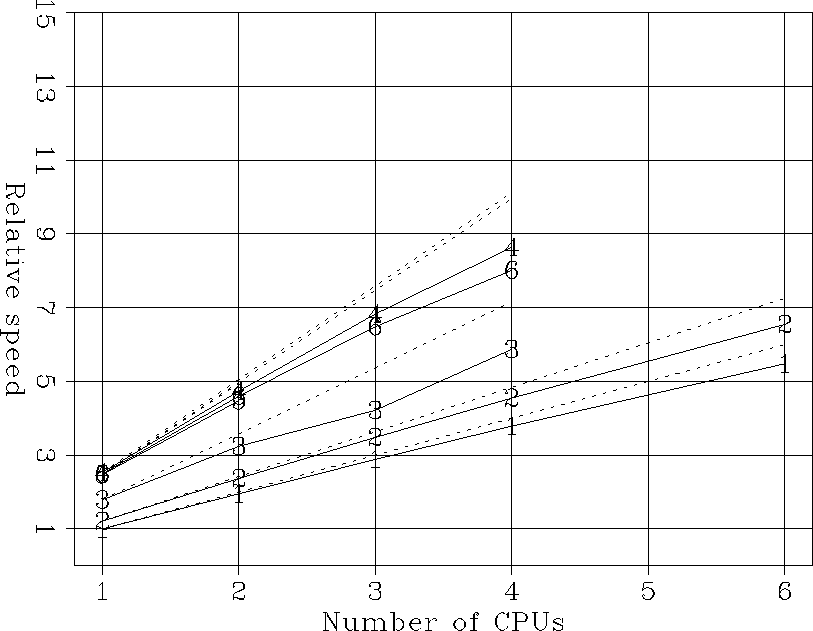
Figure 4
shows the relative speeds for all the computations
performed to solve the large problem,
excluded one-time initializations.
In relative terms,
the SGIs performs better than
Intel-based computers for this large problems,
both as single-CPU speed and as parallel speed up.
The MIPS-processors' performances
are less affected by out-of-cache computations
than the Pentium III's
because the memory bandwidth of the SGI systems
is better balanced with the CPU speed.
Actually, for the large problem,
the parallel speed-up improves on the SGIs
because
the large problem is more computationally
intensive than the small one,
and thus the serial I/O are less of an handicap.
On the contrary, the parallel speed-up
of the Pentiums is little worse than
for the small problems.
This is a possible indication of memory contentions
between threads in accessing memory.
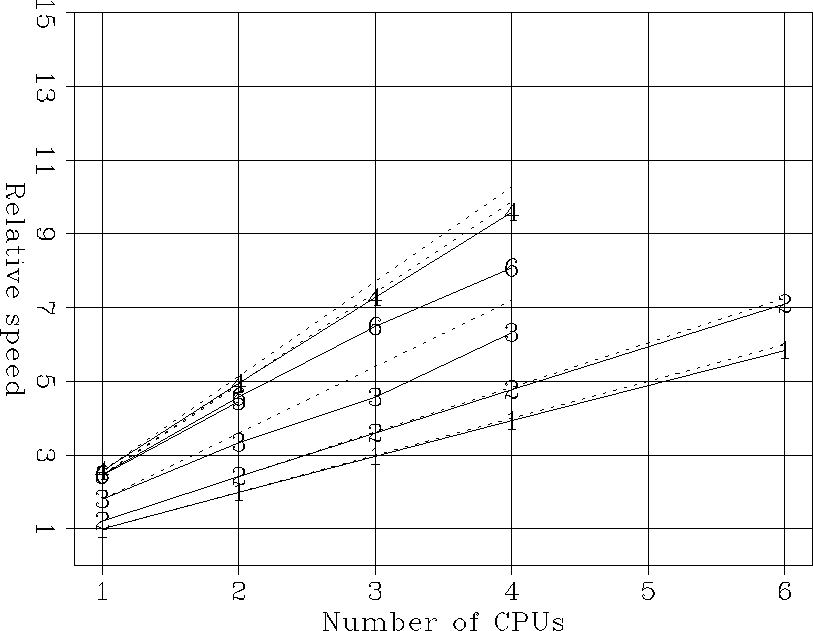
Figure 5
shows the relative speeds for all the computations performed in parallel.
The SGIs show almost perfect parallel speed-up,
indicating no contentions in accessing memory.
On the contrary, the parallel speed-up
on the Xeon is similar to the one shown in
Figure 4,
indicating that the loss in parallel efficiency
is likely caused by memory contentions,
and not by the serial I/Os.
Somewhat surprisingly,
the FFTs seem to run in parallel without loss
of performances on all machines (Figure 6),
with the exception of the dual-processor Pentium.
It is possible that the memory access pattern of FFTs
benefits from the larger and faster caches
more than the rest of the computations.
Large-All
Figure 4
Relative speeds as a function of number of CPU for
all the computations in the large problem:
1) Power Challenge (FFTW),
2) Power Challenge (SGILIB),
3) O200 (FFTW),
4) O200 (SGILIB),
5) Dual-processor Pentium III (FFTW),
6) Four-processor Xeon (FFTW).
One processor Power Challenge has a speed of 1.
The dashed lines correspond to the ideal parallel speed up.

Large-par-All
Figure 5
Relative speeds as a function of number of CPU for
all the parallel computations in the large problem:
1) Power Challenge (FFTW),
2) Power Challenge (SGILIB),
3) O200 (FFTW),
4) O200 (SGILIB),
5) Dual-processor Pentium III (FFTW),
6) Four-processor Xeon (FFTW).
One processor Power Challenge has a speed of 1.
The dashed lines correspond to the ideal parallel speed up.
Large-fft-All
Figure 6
Relative speeds as a function of number of CPU for
the computations of the FFTs in the large problem:
1) Power Challenge (FFTW),
2) Power Challenge (SGILIB),
3) O200 (FFTW),
4) O200 (SGILIB),
5) Dual-processor Pentium III (FFTW),
6) Four-processor Xeon (FFTW).
One processor Power Challenge has a speed of 1.
The dashed lines correspond to the ideal parallel speed up.
Next: KIRCHHOFF MIGRATION
Up: SPLIT-STEP MIGRATION
Previous: Small problem results
Stanford Exploration Project
10/25/1999