




|
seegap
Figure 9 The lines are the gaps between successive vessel tracks, i.e., where the vessel turned off the depth sounder. At the end of each track is a potential glitch. | 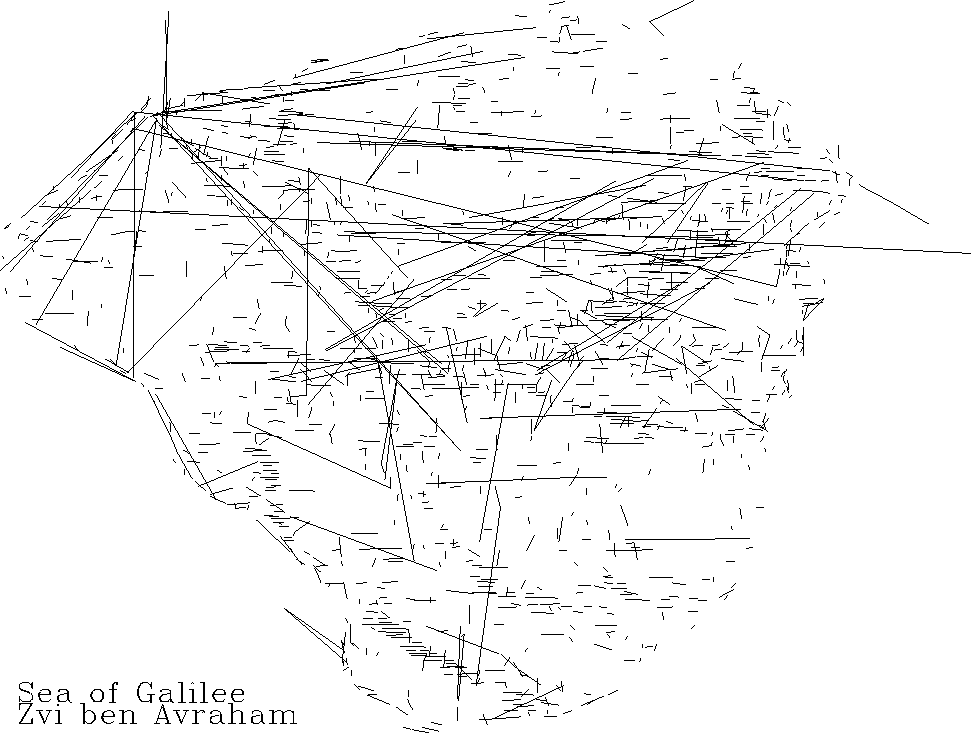 |





Besides these processing defects, the defective data values really should be removed. The survey equipment seemed to run reliably about 99% of the time but when it failed, it often failed for multiple measurements. Even with a five-point running median (which reduces resolution accordingly), we are left with numerous doubtful blips in the data. We also see a few points and vessel tracks outside the lake (!); these problems suggest that the navigation equipment is also subject to occasional failure and that a few tracks inside the lake may also be mispositioned.
Rather than begin hand-editing the data, I suggest the following processing scheme: To judge the quality of any particular data-point, we need to find from each of two other nearby tracks the nearest data point. If the depth at our point is nearly the same depth of either of the two then we judge it to be good. We need two other tracks and not two points from a single other track because bad points often come in bunches.
I plan to break the data analysis into tracks. A new track will be started wherever (xi-xi-1)2 + (yi-yi-1)2 exceeds a threshold. Additionally, a new track will be started whenever the apparent water-bottom slope exceeds a threshold. After that, I will add a fourth column to the (xi,yi,zi) triplets, a weighting function wi which will be set to zero in short tracks. As you might imagine, this will involve a little extra clutter in the programs. The easy part is the extra weighting function that comes along with the data. More awkward is that loops over data space become two loops, one over tracks and one within a track.